
Hi there AppWorks fans,
Welcome to a new installment of AppWorks tips.
A tip from the pro’s; Always prepare yourself for the winter to come. Trust me, eventually you will hit the wall and that’s the moment where your administrator of the AppWorks platform would thank you if you made a fine solution to make sure the tower of AppWorks power is not collapsing under the stress. What a nonsense!? You get what I try to say…right? 🤣
Let’s go thought some implementation scenarios on how to overcome your worst nightmares in the BPM space…
Let’s get right into it…
First, a hard commitment! Don’t use the short-lived execution mode for a BPM which calls external services…EVER, unless you really can’t do it differently, or if it doesn’t matter to completely restart the BPM, or you need direct feedback in runtime!…So, again…It depends, but always ReThink about it!. Services will be down; nothing is 100% up and running. For services within the platform this is no issue; When TomEE is down nothing works! 🙃 Only, you can still get a wrong input which still can result in a failed service call (also internally!). Don’t overengineer it all but think where things can go wrong and protect the system from collateral damage.
You can download the implemented examples shown below here. We make use of the external Star Wars API which also requires you to have an HTTP service container up and running from the ‘System Resource Manager’ artifact; Read all about it here!
We also make use of internal services via the service container of type ‘Application Server’.
…
So, prepare yourself with these 2 service containers!
Catch the exception
An exception can occur on any circumstances, like a service is not available, not bringing a valid input to a call, or something else went wrong on the other side of the line (in the external system). Enough reasons to catch it once it goes wrong…Trust me, any service goes wrong one time in the future. Like in programming (which is similar to BPM modelling), we can catch the error and do something with in; Like simply “swallow it” and continue life…A bad habit with a #RED_FLAG, but it is a valid scenario! It’s better to do something with it; Like inform somebody to have a look at it. You can drop a task in the administrator inbox where manual (or automatic) restoring/reverting to previous activities can be a possibility. I know…It all depends, but have a look at these examples:
❇ Swallow and continue life (Please, don’t do it like this!) - eXample1
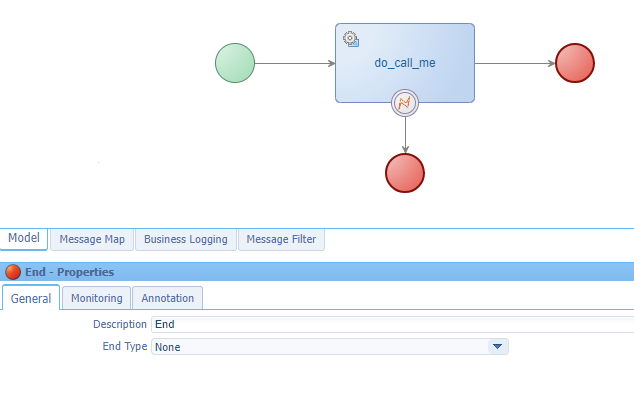
This will also look like a ‘Completed’ BPM from the PIM perspective although something is breaking down! #NOT_WHAT_YOU_WANT
Always make sure, you send back a message to the world at least something is going wrong:
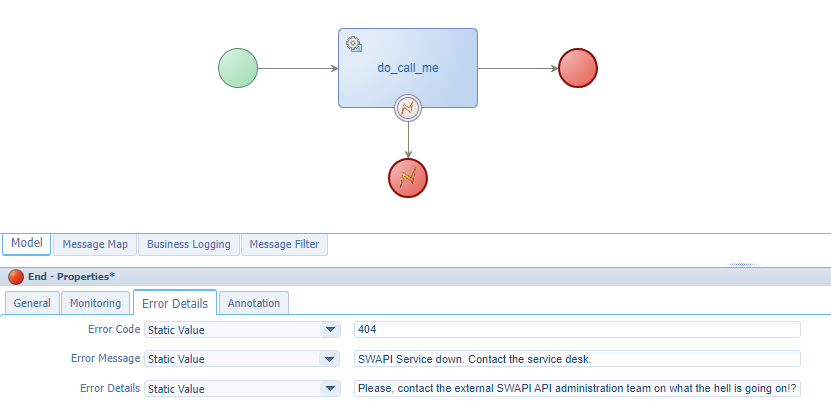
In runtime, your end-users (and administrators) will love you for it:
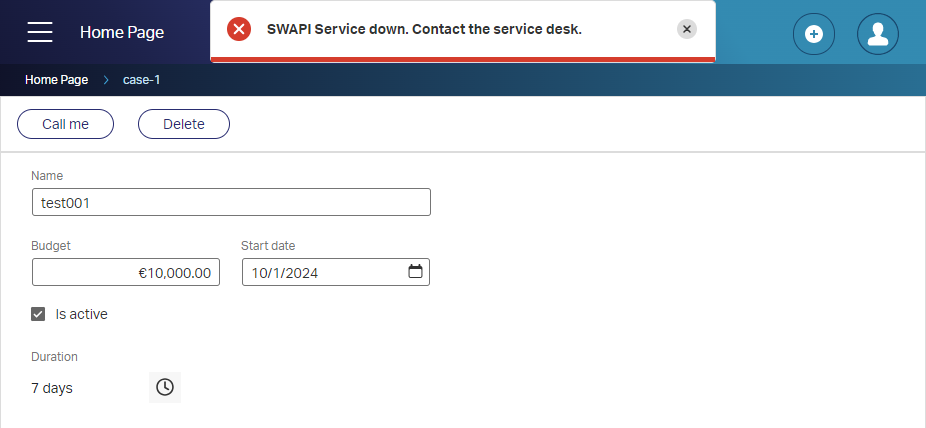
FYI: I stopped my HTTP service container to trigger the error! We could also use an out-of-the-box platform service with no input, but then we don’t have the SWAPI fun (which I wanted to try out once)! 🤓
❇ Log to a location and solve the back-end manually later - eXample2
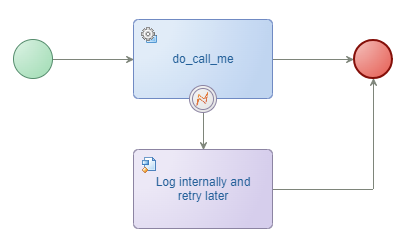
This situation will complete the BPM nicely in the PIM with a location “to be determined”; For this post I start a bpm_no_ops BPM to fake it.
❇ Hold, collaborate, and decide what to do - eXample3
Here it directly gets more complicated:
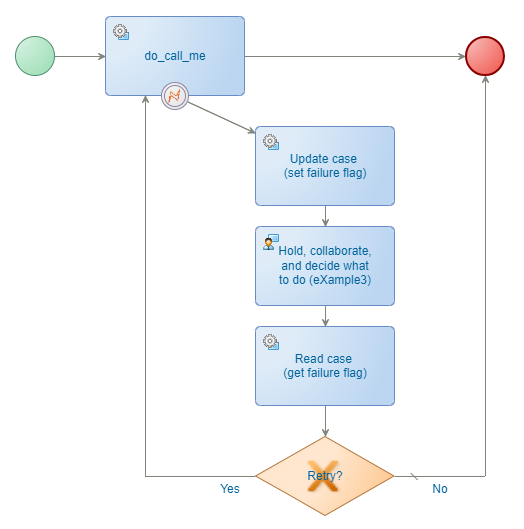
Now you put the choice into runtime where someone (in my case the process initiator) needs to make a choice what to do next (which is our “failing flag”!):
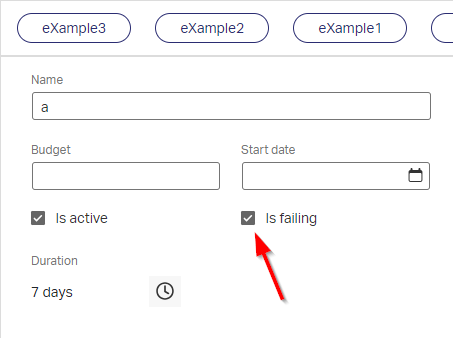
Based on this, we do a retry, or we continue life and accept it with an xPath-check like this: ns10:ReadcaseOutput/ns10:ReadcaseResponse/ns11:case/ns11:case_is_failing/text() = 'false' (the “NO” choice is the default exit for the exclusive-decision-construct…at the bottom of the previous screenshot!)
Notes:
- You also see an ‘entityTask’ layout attached to it for that “Hold”! Don’t forget this as it will create a task to pick up instead of ending up in an endless loop. For a BPM this works slightly different from ‘Lifecycle’ BB activities where you are (by default!) the task owner if you don’t configure anything!
- This layout is only possible when you add the ‘Lifecycle’ BB to the entity, but you can leave the implementation empty! WHAT!? Read here
❇ Restore previous steps and retry after collaboration - eXample4
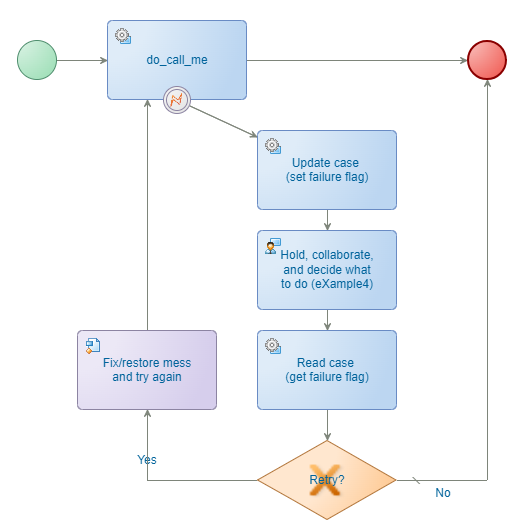
It’s the same as the previous example, but once you decide to retry, you get the chance to “automatically” fix things on the input (if required!)…It all depends, but now you see what is possible.
…
Interesting notes during my try-outs.
⁉ Two output flows on an activity doesn’t show a popup screen magically for the end-user to choose from on the manual task; So, like this (which is publishable):
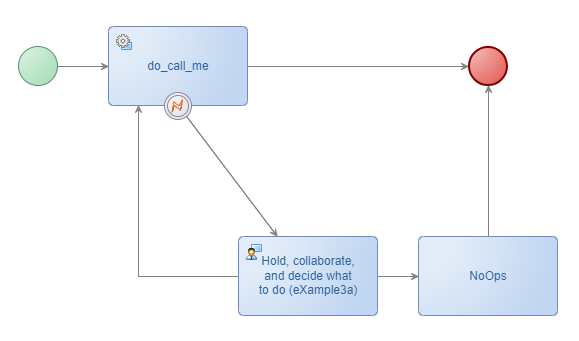
I expected a popup behavior, but with AppWorks it works slightly different from what I saw in the past with tools from Documentum (like the “Business Process Manager” or the older “Workflow Manager”…Yes, great memories from my career!)
Ohww…The NoOps activity is there to make the BPM publishable, but still…I see the BPM keeps looping back to the manual task when I complete it; My NoOps is never called…Or it could be me with a different understanding and expectation; Have a comment below!
⁉ eXample3 and eXample4 both run a BPM in long-lived execution mode. I was always in the assumption the UI does not get a live update, but it does trigger a refresh on my form where the “failure flag” changes…Directly on the fly! This could also be the task layout which is available in my layout; Not sure, but it’s unexpected behavior in positive sense! 🤫
The “admin” task
This can be as simple as an activity to a functional administrator role, but we can also create an instance of our own low-code ‘Notification’ entity exposed via a list accessible again for the admin role.
❇ An admin task to a role - eXample5
This one extends eXample3 and eXample4 where we send the task to a specific role (fun_admin in my case):
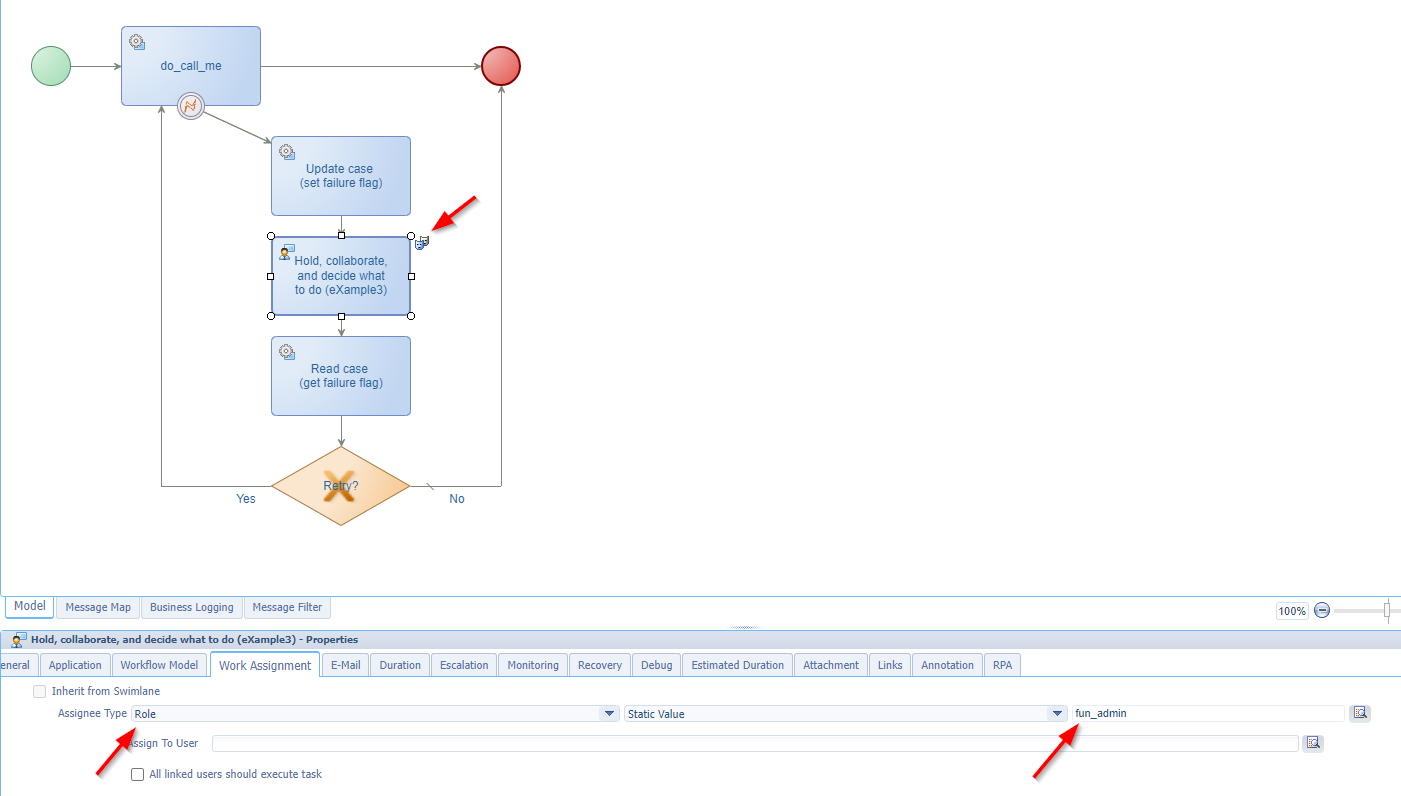
The task will get a delivery at a group of users (make sure you assign your users from the ‘User Manager’ artifact) where one of the admin-user can claim the task, make the choice, and continue life.
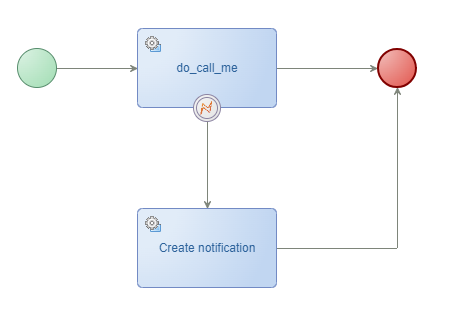
❇ ‘Notification’ entity creation - eXample6
This scenario depends on a service container of type ‘Application Server’; Have a search on this site to find plenty of examples. For this scenario we create a new entity ‘Notification’ which relates to a case and has the ‘Create’ operation available from the ‘Web service’ building block. On failure, we create an instance which the admin group can monitor manually via the default list in the UI, or they further automate it in a dashboard calling the FindAllnotification webservice. You can read here how to externally call an exposed AppWorks service (incl. OTDS authentication!)
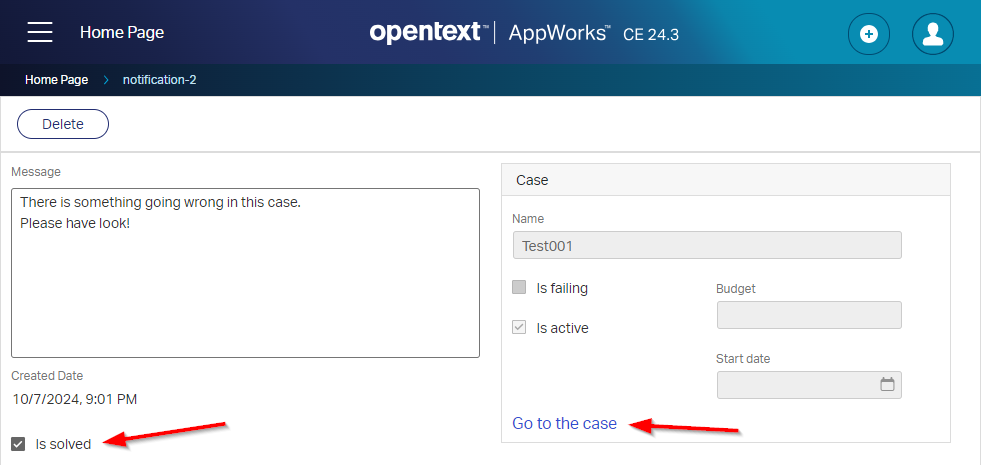
In runtime, you’ll get a notification which the admin people can solve:
From an automatic monitoring perspective, it’s possible to regularly do a call like this (cleaned from namespace details):
1 | <SOAP:Envelope> |
With a sample result like this:
1 | <data> |
Read this post to get more creative thoughts on ways of extending “notifications”.
This is a simple example, but other options can be sending an email, publish a JMS request, do an HTTP/FTP call…Or any other call for extra help; Be creative!
All above examples are just a quick and simple implementation which you can extend to your own needs; Again, don’t overengineer things! Simplicity and elegance rules over complexity and hard to understand BPMs.
Let’s jump to the next section…
Retry loop with index - eXample7
This one requires some work as you need to keep track of an index (as BPM variable) to know when enough is enough. You can produce something like this where you have more control on what exactly needs to happen:
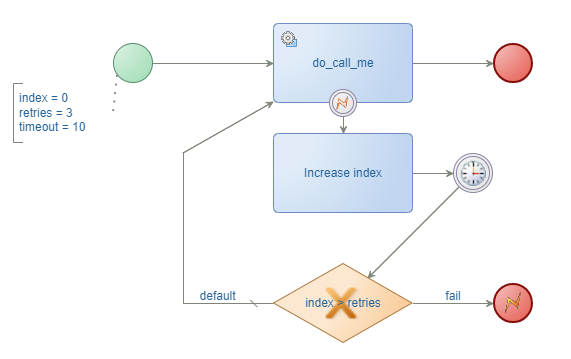
You don’t see it in the screenshot, but the ‘Delay’ construct gets a timeout in format
P0Y0M0DT0H0M10S. You’ll see it when you download the solution. Read about this duration format here
Service activity “retry” option - eXample8
You can also make it yourself easy and configure the retry option on an activity:
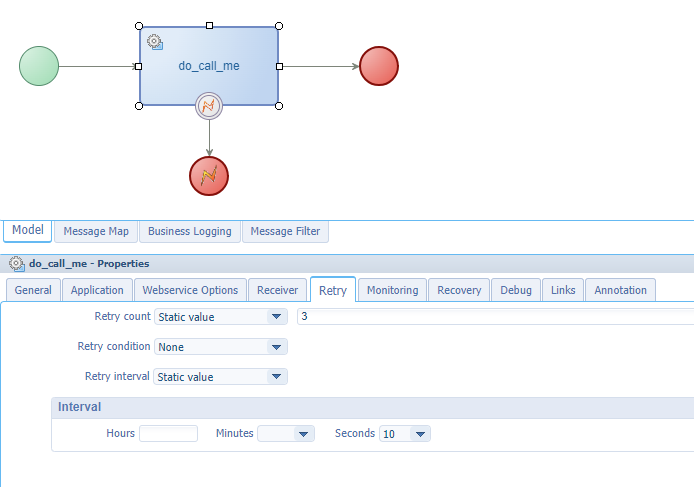
Notes on this function:
- The BPM must have a long-lived execution mode.
- Be aware this simply calls the same action again with the same input. If the input is already wrong, you can hit it repeatedly, but eventually you still need to catch it for your own bad input.
- The instance will sit and wait the retry-count times the interval before the whole flow completes/aborts. So, you always need to find the right spot for not waiting tooooo long, but enough time to solve the problem on the other side of the line before the flow completely aborts.
How nice…A worst-case “DONE” for this week, where different scenarios expose their low-code power on avoiding failure in your BPM implementations. Make sure to always think about these scenarios as somewhere in the future #&&@%&*! will hit the fan; and the last thing you want is an aborted BPM instance with a lot of manual maintenance tasks for your administrators. Be aware and have a great weekend.
Don’t forget to subscribe to get updates on the activities happening on this site. Have you noticed the quiz where you find out if you are also “The AppWorks guy”?
