
Hi there AppWorks fans,
Welcome to a new installment of AppWorks tips.
It’s the last post for 2023, so let’s make it a good one! This post will please your managers as those are always the ones complaining, requesting, and asking where the documentation part of the project went off track. Yes my friend…in my project this was also “a thing”, but not after a great insight from a colleague that triggered me for this interesting post. Have you ever used this “Annotations” tab available on any document you create (it’s in the properties of the context menu)?

Well, I didn’t! But what did trigger with me, is the possibility to track the save location of this data, read it with a webservice, use this WS in a BPM and format it to a great PDF file!?!? Or better, use XSLT to transform to generate an HTML page!
How about those good old Apache FOP days and create our own connector out of it…Now we’re talking, but I’ll just keep on dreaming! Too bad a day only has 24 hours…We simply print the HTML with a PDF printer (if required these days)!
Let’s get right into it…
Time to track down our annotation Hello there! (from the screenshot above)…For this, I already prepared my Postgres DB spitting out logging at a higher level (I explained this already 10 times, so have a search for log_statement to figure out this trick).
With the monitoring open on the Postgres logfile sudo tail -999f /var/lib/pgsql/data/log/postgresql-{day}.log | grep -i "Hello there!" I found an insert statement on the table ‘XDS_DOCUMENT’! So, this should get a result:
1 | SELECT name, internal_name, created_by, created_date, lastmodified_by, |
I use HeidiSQL to run this SQL statement and I use SQLFormat to make it look great for you! 😉
Looking at the data, these columns are enough for now:
1 | SELECT name, |

Great, but we can do better with a statement like this:
1 | SELECT name, |
WHAT? WHY? HOW ON EARTH?…Yes, have a ReThink first on what we try to do here!?
…
We only want to get the annotations that have a starting trigger MANUAL. So, like this:

The substring(annotation, 8) part makes sure to skip the trigger text in the outcome…How smart! 😅 Why 8 characters? Well, that includes the <Enter>!
…
Great, but what can we do with these details? Well, how about using the WS-AppServer connector to read this database table with our trigger text? Now we’re talking! If you don’t have a clue, it’s time to consume yourself first on the popular “Northwind DB” post
In quick steps to continue our post:
- Create a new service group from the ‘System Resource Manager’ (just in your own organization!)
- Use the
WS-AppServerconnector to start with - The service group name is:
sg_ws_appserver- Select all the service interfaces
- The service container name is:
sc_ws_appserver- Assign it to the OS process
- Make it start automatically
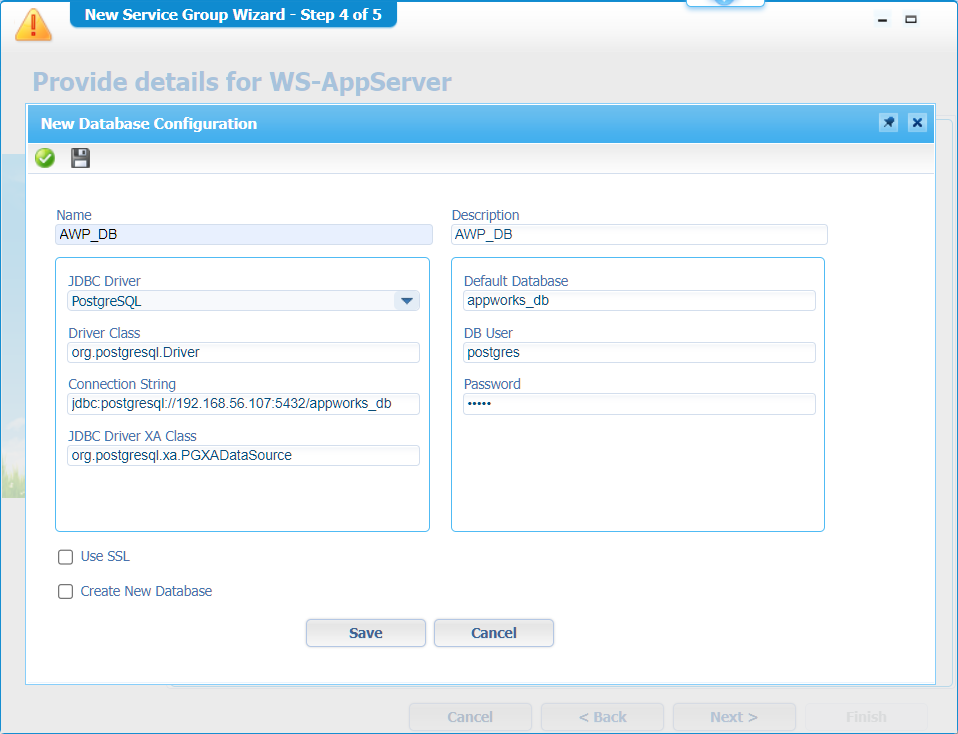
- In the database configuration screen, you can create a new connection to the AppWorks DB!
- With connection string
jdbc:postgresql://{host}:{port}/{db_name}:![docs_004]()
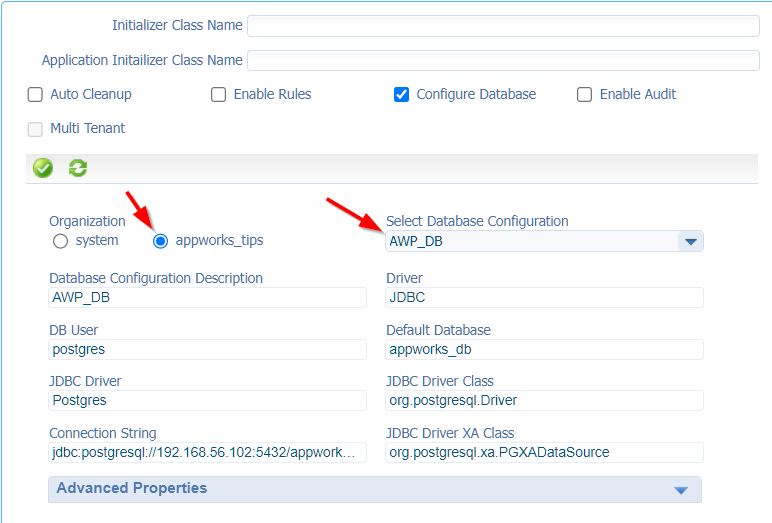
- Within your own organization:
![docs_005]()
- With connection string
- Finish the wizard and make sure the service container starts with a green icon
…
With this service container in place, we now create a new type of document called ‘Database Metadata’; Nicely in our project folder masterdata. This is what it will look like after retrieving the tables and moving it to the right panel for consumption:

Is it smart doing it like this? I ReThink it’s better to create a view for the table and use this instead! I’m not a database person, but this “feels” more solid as you will see also related tables moving to the right as they are (I guess!?) related. I leave that view-task with you!)…We use the tables for now!
Save it, and close it…There is no need for a publication (as far as I can see); Just expand the tree in your project and right-click our new injected table for a great action to select:

The next screen is just a query builder…Guess what query it should be! Make it like this and finish it up with the greatest button (😍) of the platform:

It starts a new screen which you just point into the correct direction for naming convention and save location…And then…GENERATE!

The result/outcome? Have a look in your project:

Right-click, publish it first, and assess it with a test operation:
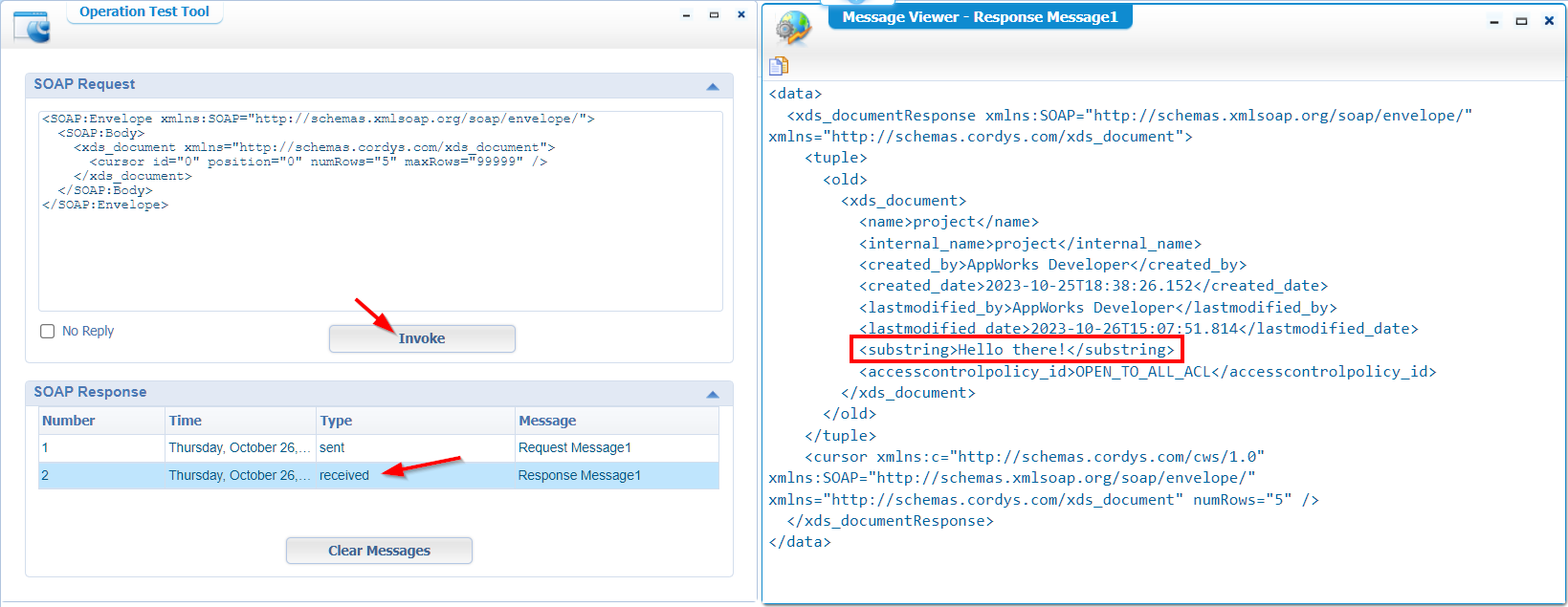
It’s a PARTY!! 🎉 🥳
…
What is the next step? Well, we now just need to convert this data via XSLT into a nice-looking format.
WAIT…Why don’t we ask ChatGPT to generate an XSLT part that plots our data into an HTML table!!…Ohwhwhw YEAH!
This is my input XML and this is my chat history with ChatGPT:
1 | ME: Good evening my dear XSLT expert...Can you help me? |
#WTF just happened…😱
This is the generated XSLT
This is the generated HTML

I guess we can all stay at home now! 😛 No further adjustment needed…
…
What to do with this ChatGPT output? Well, how about further fine-tuning it, use it in a BPM (with the services xds_document and XSLtransformGeneric) and output the HTML file to the server with WriteFile (or as e-mail attachment in Base64 string with service SendMail…Have a search to find more about these services!).
Just a final documentation thought for the new year to come
Now that we have this in place, I would just want to trigger some creativity to extend the documentation part:
- Make use of the Markdown language to document your annotation; You can render PDFs out of markdown data with Pandoc! I use Markdown also for this website content! Orrrrr…use XML in your annotations!
- Read your SVN history data; With “smart” commit messages (in XML?) you can do magic in your release documentation.
- I haven’t tried it, but could it be possible to plot a BPM or entity lifecycle overview in a PDF!? I know you have a print preview functionality which simply executes a
printModelwebservice and saving it as JPEG on the server under:/opt/opentext/AppWorksPlatform/defaultInst/webroot/wcpdev/cas/vcm/temp/...! - Or what about reading the BPM comment-constructs as well…It’s all saved somewhere!?
- If you use Jira/Confluence, you can even grab the data and further extend your documentation.
You see, possibilities enough; Ask yourself also the question when enough is enough! 😉
How it that for a final post for the year? I give it a DONE where we opened new creative ways to generate solution documentation out of the “Annotations” tab for a specific document. We even brought you some new-year-ideas on how to further improve on documentation generation. I say, a great final post, for a great final year…Have a good one, and I see you in the next year with more to explore on AppWorks Tips! Cheers… 🍻
Don’t forget to subscribe to get updates on the activities happening on this site. Have you noticed the quiz where you find out if you are also “The AppWorks guy”?
