
Hi there “Process Automation” fans,
Welcome to a new installment of “Process Automation” tips.
Vacation time is getting closer and closer! The temperature outside is rising…So, it’s about time to put our VM under some stress with a fun eXperience. Let’s build a BPM that keeps creating entities until things collapse and eXplore/learn what’s left after failure!
Just some question upfront that keep me curious:
- How long does it take? I hope it’s days, but let’s see!
- What will break first? The DB, XDS, CARS, TomEE, or anything else!?
- Can we even access the system after failure?
- And how about the business ID? That’s an interesting one explored before here
Let’s get right into it…
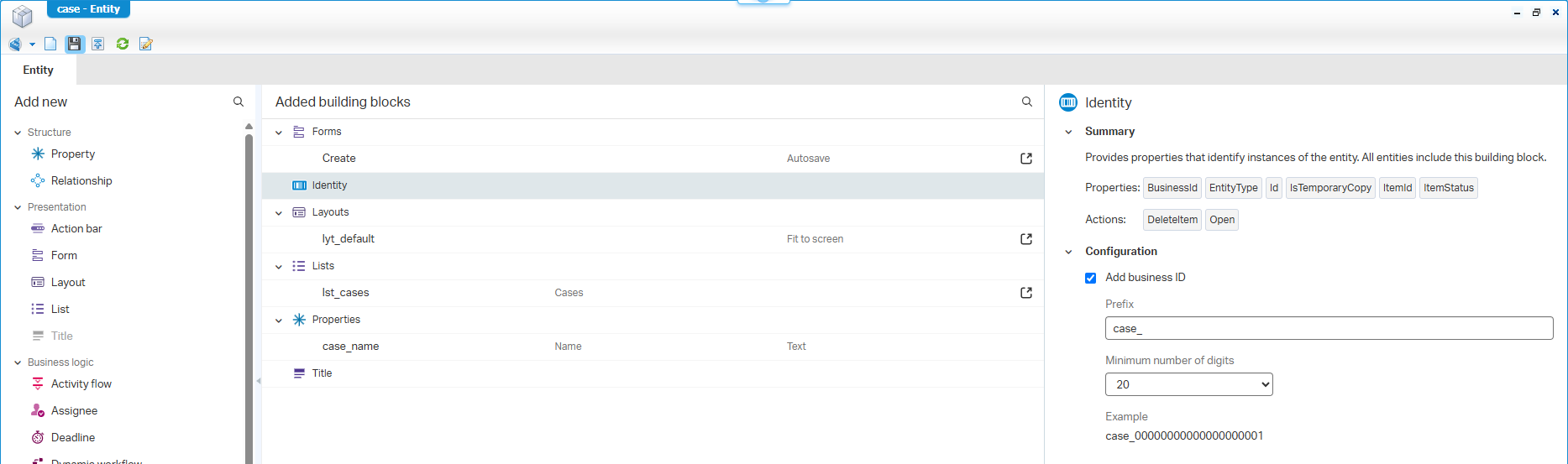
Boot up your VM, create yourself a nice workspace with project, and create the first entity. It can be anything with some properties you like where I at least add the business ID with a setting like this:
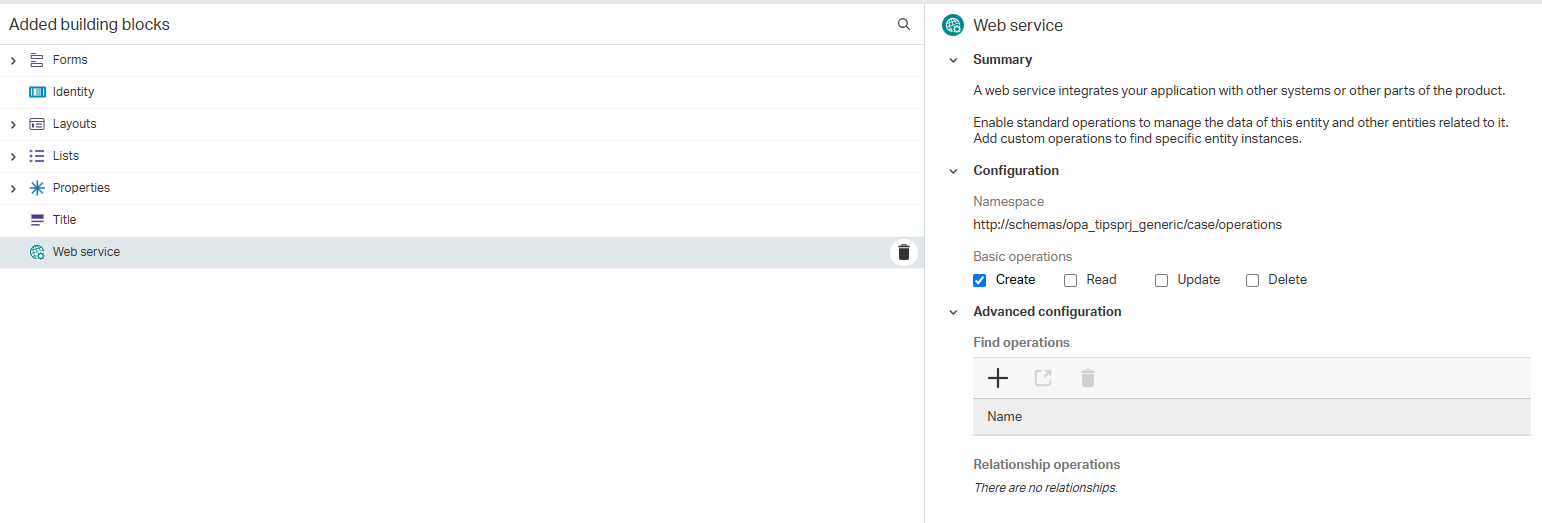
Next, we also add the ‘Web service’ building with the ‘Create’ operation:
AND we also add the ‘Tracking’ building to the entity to get some more creation details in the database.
For a better view in runtime, I also update my ‘List’ BB with additional properties:
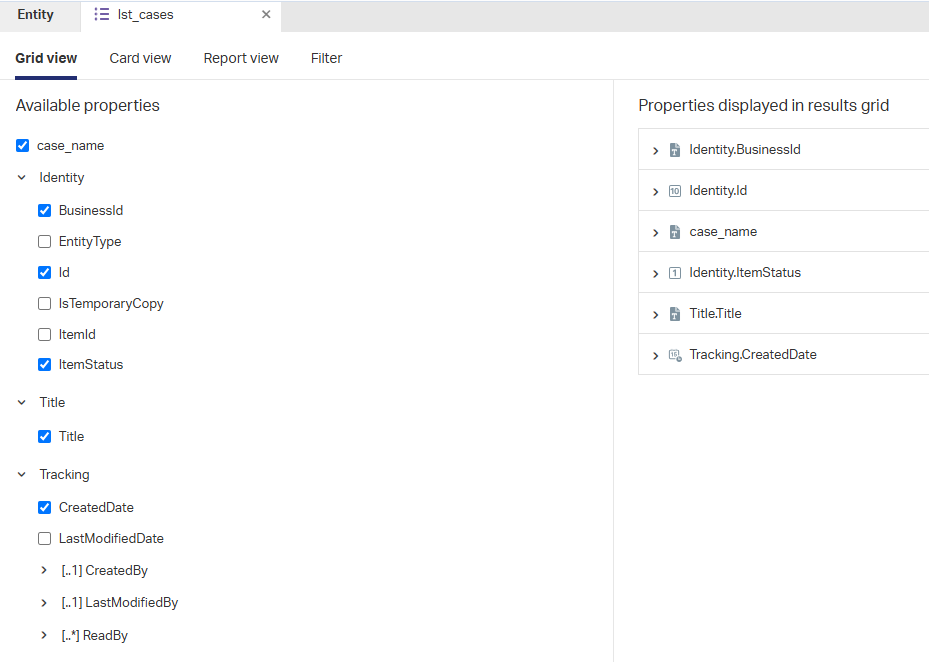
Do a save and a publication; You should be fine in runtime…Give it a shot yourself.
…
Because of the ‘Web service’ BB, we require a new service container from the ‘System Resource Manager’ artifact with this input:
- Connector:
Application Server Connector - Group name:
sg_appserver - Web Service Interfaces: Mark the
Method Set Entity case(available after publication!) - Service name:
sc_appserver - Startup automatically
- Assign to the OS process (as recommended for each service container by OpenText support!)
…
❗DON’T TRY THIS AT HOME❗
Now for our endless looping entity creation BPM…Well, that as easy as this:
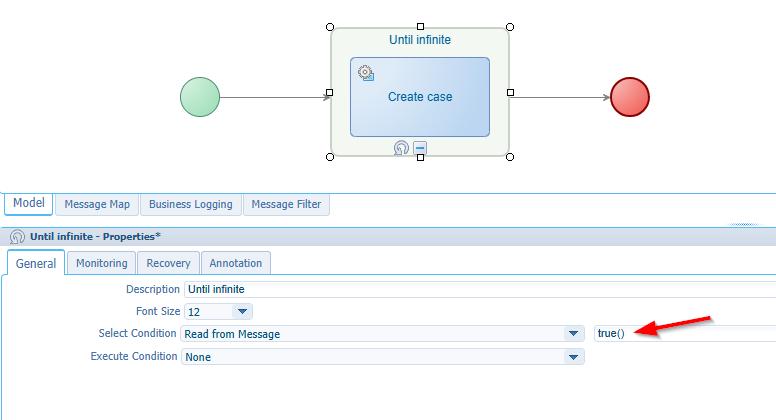
Notes:
- Is this publishable? Yes it is!
- You can inject the create operation for your entity from the activity context menu.
- You find the “until”-loop in the context menu of the activity.
- Watch out you connect the flows to the “Until” loop box; not to the activity…A common mistake!
I also make sure to make a messagemap like this on the create operation:
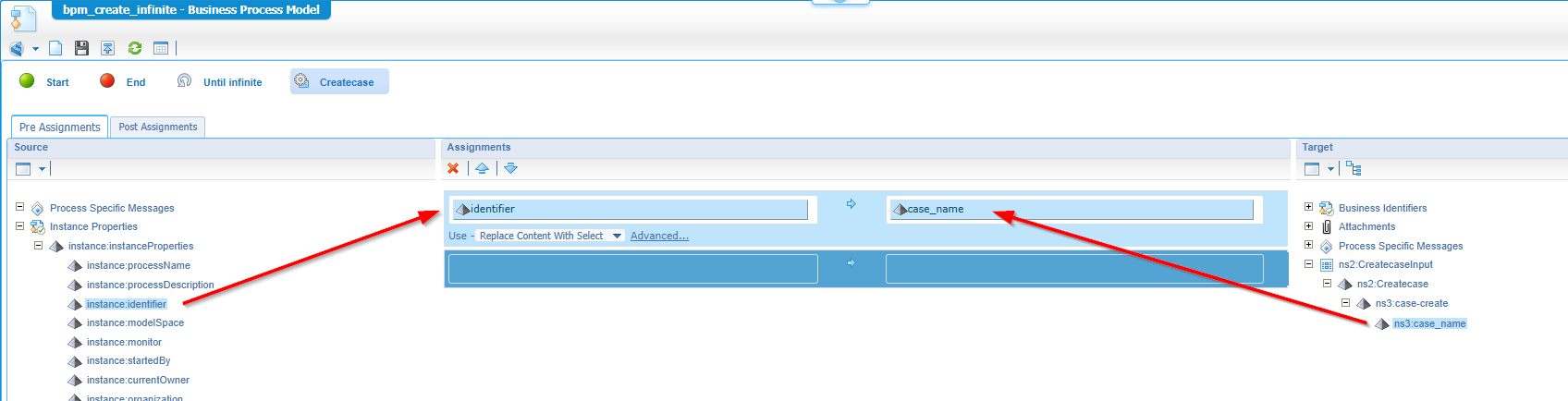
I thought you didn’t require this mapping (as my property isn’t required either), but during my first test-run I conclude no creation happens when there is no assignment in place for my ‘Create’ service call!? Strange, but it’s what it is! #SUPPORT…Or is it an intended feature? You tell me in the comments.
Save the BPM with an interesting name, publish it, and hold your breath before executing!
Ready, set, GOOOOO!
Hmmmm….The PIM tells me this on the aborted BPM instance:
Rule/Expression evaluation failed. Error while evaluating the condition true. Error is : Result type is not XPATH_BOOLEAN
WHAT!?!?
Ok, let’s change from true() to 0=0 as a condition!?
Hmmmm…That the same issue!?!?
Ok, let’s level up to a condition like this one (which is still “infinite” true): instance:instanceProperties/instance:rootInstanceType/text() != 'PROCESS'
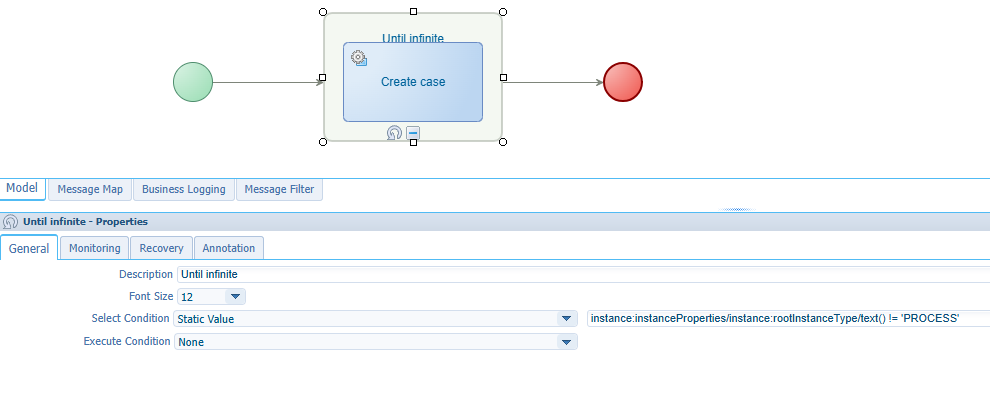
This will run it for sure…And it is! Trust me on it. 😇
I also disable the monitoring for our BPM to a more acceptable level before my long-running assessment will execute:
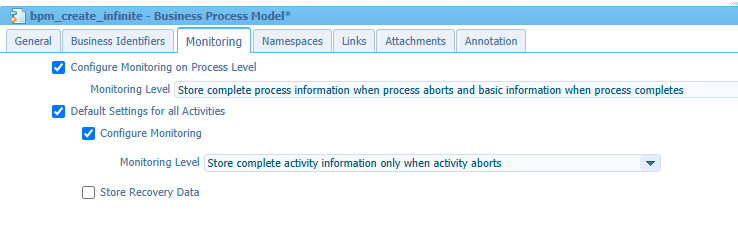
By the way; These levels are a great rule of thumb for every BPM for any solution!
Time for our run with <F12> in the BPM designer…AND sit and wait until collapsion/collapsation!?
The results
After a first 15 min. run (as I’m simply curious) a view via HeidiSQL on the Postgres DB:
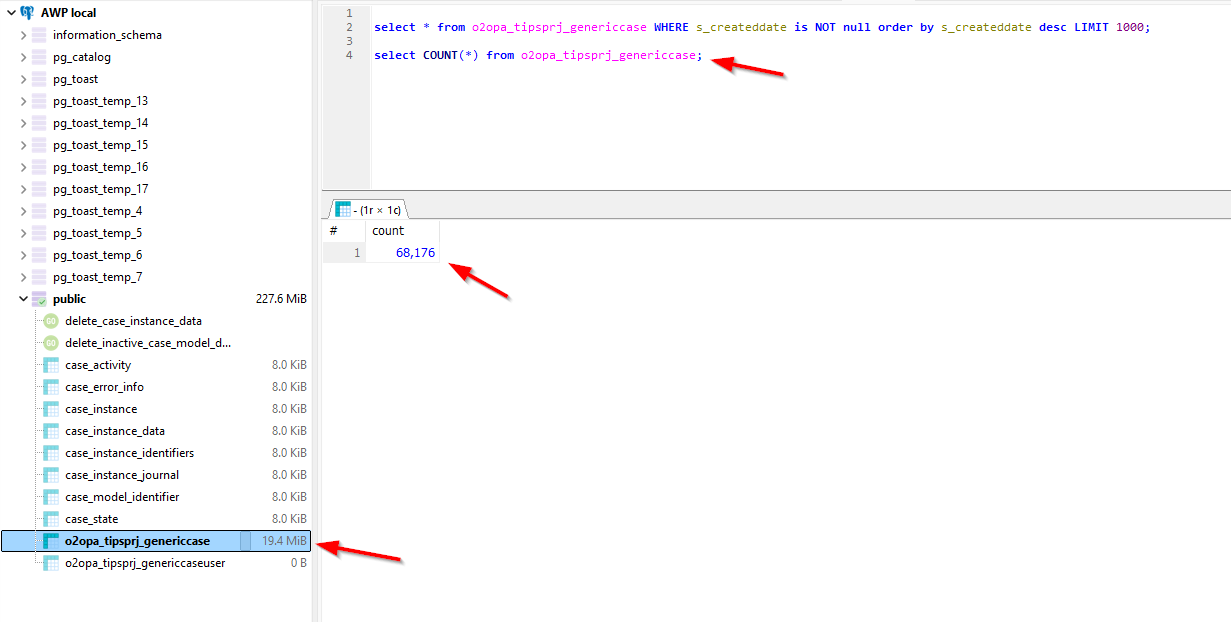
1 | SELECT * |
…
I lost time, but I think we’re almost 2 hours later…The counter is on 500K entries, and nothing breaks/fails (only some fan-blowing!)
It’s about time to heat-up with a second instance of the BPM! 🙈
AND…Especially for you, I start a third instance too. #YOLO
Time for dinner…
…
Two hours later; Counter at 2.9M entries and 825Mb table size! Interesting…And still running smoothly, but some small cracks in the Application_server.xml:
1 | <log4j:event> |
And cracks in the TomEE catalina.out:
1 | "Thread-435" #1243 daemon prio=5 os_prio=0 cpu=1.53ms elapsed=0.90s tid=0x00007fd9cc850c60 nid=0x1f73 waiting on condition [0x00007fd9040d3000] |
We’re still running, so hit the gazzzzzzz again with 2 extra BPM instances (now 5 running infinite-creation-loop instances)!
UI is still responsive to work with…Even filtering and sorting on the list in runtime feels smooth.
Time for a movie with my wife and kids…In the evening I close my VM with a “suspend” on the BPM instances!
…
The next day, I boot my VM again and do a resume on the suspended BPMs. About 4-5 hours later (after lunch) I hit the 10M entries with 2.8Gb on the table size! No further cracks or problems (except for the “Java Heap” usage)….Fascinating; That’s a pretty stable system if I may say so!
Shall we wait? What else can we do to break it!? I take a weekend to think about it (with the VM down), but it looks to me that disk-size will eventually be the bottleneck and that’s not something to wait for on my 4T disk-space! 😉
…
Monday morning…I got an idea! Let’s increase the next value of the business ID value to a value of 99999999999999999990 (20 characters to be precise; Pronounce it as “ten less than 100 quintillion”). I have never, ever seen such number of cases in a system (let me know if you’re the lucky one!)…How can we change this number? Well, read about it here explaining the principles of database sequences!
What I also do is increasing the prefix of my business ID with also 20 chars: case_case_case_case_! Why? Here’s why:
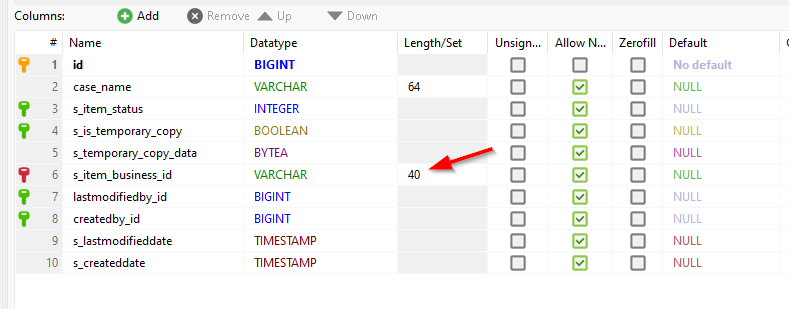
So, our next case creation (first by hand!) should have a business ID of case_case_case_case_99999999999999999991…Agree? Well, not completely!? Keep on reading…
…
These are the queries to find and set the sequence for my ‘case’ entity to the needed value:
1 | SELECT * |
You can read what will happen after this number here
Hmmmmm…That’s an error:
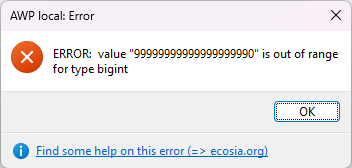
So, our sequence will be the bottleneck here…Aha! Let’s update the sequence to this (the largest number for a ‘bigInt’ minus 7):
1 | ALTER SEQUENCE PUBLIC.q2080027866f6aa1f080ff9c0c40dd9f54 restart WITH |
With this update our next ‘case’ instance (by hand) will now be: case_case_case_case_09223372036854775800
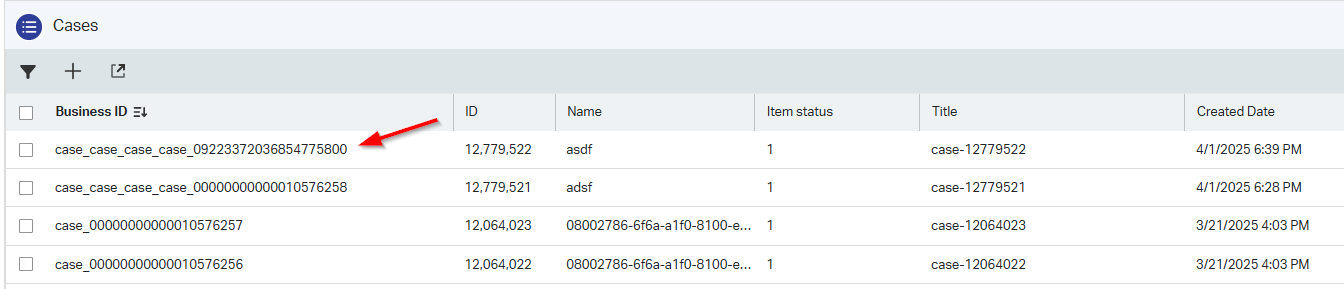
So, we’re 7 cases away from collateral damage…correct? It’s about time to resume one of our suspended BPM instances! 🙈 🙉 🙊
…
The result? Well, not as dramatic as expected. The BPM nicely aborts with an error An error occurred while attempting to access the database.. The runtime is still available with the outcome of our final destination:
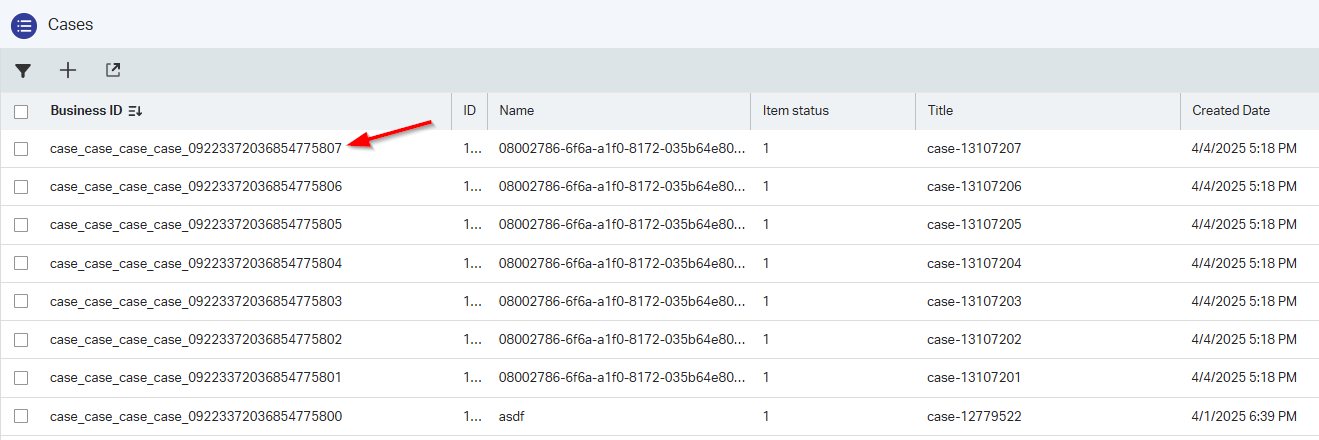
Creating a new one also gives the same error:
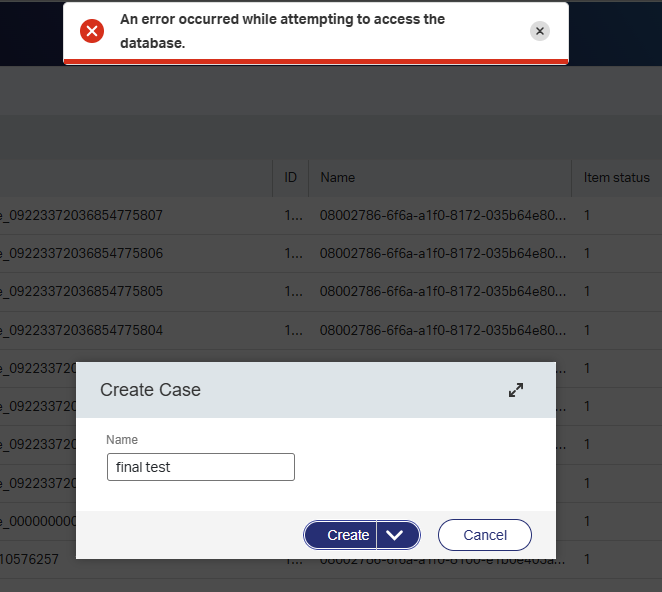
Fascinating to see as the platform itself is still fully accessible without any problems…NICEEEE! 😎
…
How can we solve this!? Well, with a strategic plan to remove old data or move it to a different location! That’s a project on itself with proper planning and eventually resetting the DB sequence to 0.
WAIT…just another thought! We have an extra preceding 0 in the 20 chars available! So, you can update all the old instances from 0XXXXXXXXXXXXXXXXXXX to 1XXXXXXXXXXXXXXXXXXX and start over the sequence from 0! You can do this 10 times, and then you’re truly at the end of your numbering, but if you have such numbers of instances? Let me know!
❗DANGER ZONE❗…Don’t do this without a proper database backup!!
These are the queries I used to make the solution workable again; directly on the database server in Linux via /usr/bin/psql -U postgres -h 127.0.0.1 opa_db. Why directly from the server? My HeidiSQL gets a timeout on my 3Gb table!
1 | --The dry-run query: |
During the above solution and a review of my own writing, I found another solution! It’s easier (and I should have known it)…You can also change your prefix of the business ID from
case_tocase2_and reset the sequence! The only disadvantage is a package deployment for your solution picking up the new prefix for the new entity instances!
You experienced a simplified collateral damage “DONE” this time. We saw the end of entity instance creation with a simple solution to solve it. I know this will never be a real situation anywhere on the world, but it’s good to know that “endless” is not “forever”. I leave it for this post; We learned the lessons; We shared knowledge; Time to continue life during a great weekend with friends and family…Cheers! 🍺
Don’t forget to subscribe to get updates on the activities happening on this site. Have you noticed the quiz where you find out if you are also “The Process Automation guy”?
