
Hi there AppWorks fans,
Welcome to a new installment of AppWorks tips.
For this week, we’ll dive into the clean-up of old BPM instances. You might already ask yourself questions about this topic. Do you see dramatic numbers in your production environment!? Each started BPM instance in runtime will get a record somewhere in the database (you’ll see!). When you instantiate 25 flows per minute we can make this rough calculation:
- Nr. of BPM instances in one year:
25 * 525.960 (minutes in one year) = 13.149.000 database entries - One BPM instance in the database takes about 2000 chars of data; One character is one byte:
2000 bytes = 2 Kb = 0,002 Mb - So, after a year we talk a table size of:
0,002 * 13.149.000 = 26.298 Mb ~ 26 Gb
Interesting to see it in numbers and lucky for you, we’ll do a deep-dive in the cleaning possibilities for these numbers…
Let’s get right into it…
Spin up your machine and make sure you have a BPM available to try out this post with me. I have a bpm_test available saved in the ‘bpms’ folder of my generic project. Just a clean and simple BPM with one activity. I run it a couple of times (after a save and publication) with the <F12> key directly from the BPM designer panel. The PIM will show us something like this:

Hmmm…the image shows my old test results from a try-out BPM. Trust me; the real test looks the same with the correct process name. This indicates I’m still a human person! 😁
Time for some investigation on where this information storage happens in the database!? I have PostgreSQL running on my RHEL VM which makes it possible to simply grab the ‘Insert’ statements with a quick log_statement setting:
1 | sudo vi /var/lib/pgsql/11/data/postgresql.conf |
After this setting we see insert statements passing by (when starting new instances…duh!) in these tables process_instance_data and process_instance. Time to have a closer look with HeidiSQL with these select statements:
SELECT * FROM process_instance_dataSELECT instance_id, process_name, start_time, end_time, description, type, user_name, status FROM process_instance
Looks like we have a clean process_instance_data table after the completion of the BPM; the process_instance still contains valuable information after BPM completion. This is one of my rows:
1 | instance_id: "0800270e-e5c1-a1ec-ab9c-dca1858128a8" |
So, now we know the storage location of our BPM information! How about cleaning it up? For this we have an interesting artifact called ‘Process Archival Manager’ from our own organization space (where we also deployed the BPM!).
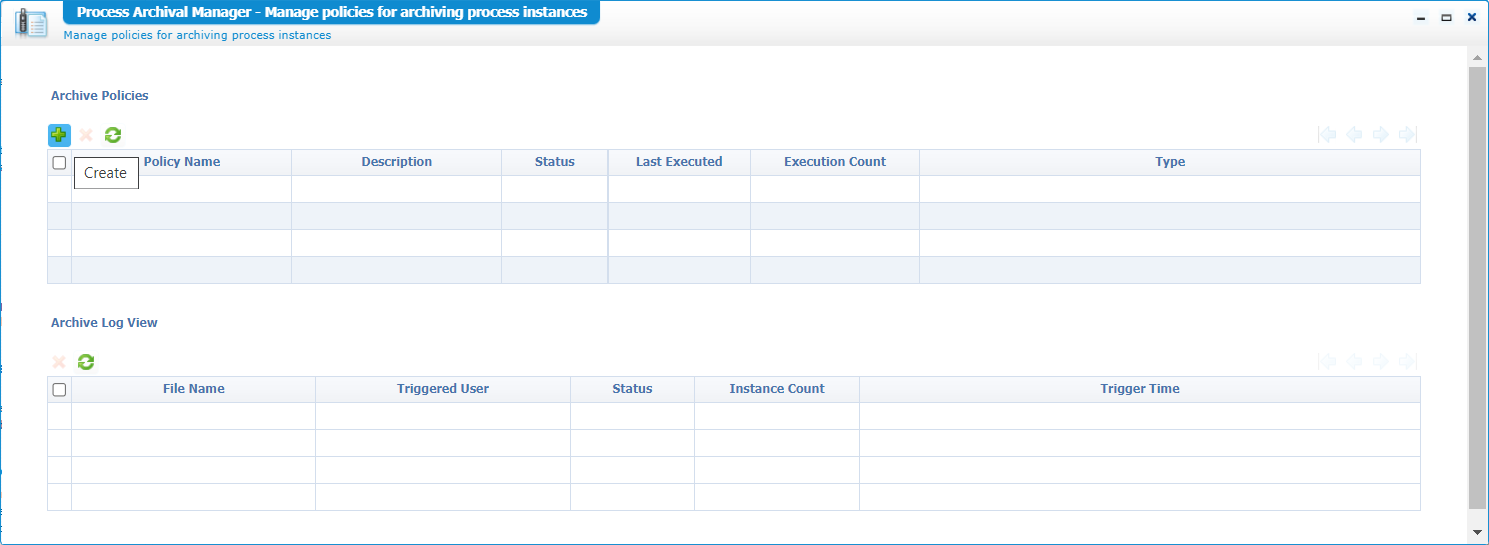
Create a new ‘Archive Policy’ like this:
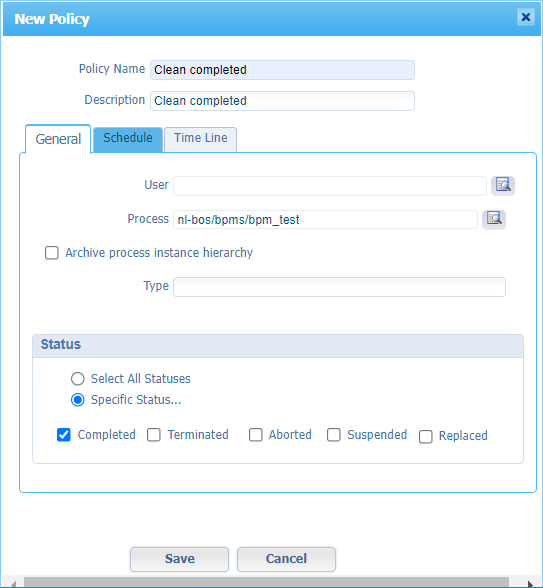
Jump to the ‘Time Line’ tab for this policy and make it ‘Older than 0 Days’. This includes the just completed BPM instances. Save the policy and do your first ‘Manual’ run from the context-menu. When done, hit that refresh icon and see the result:
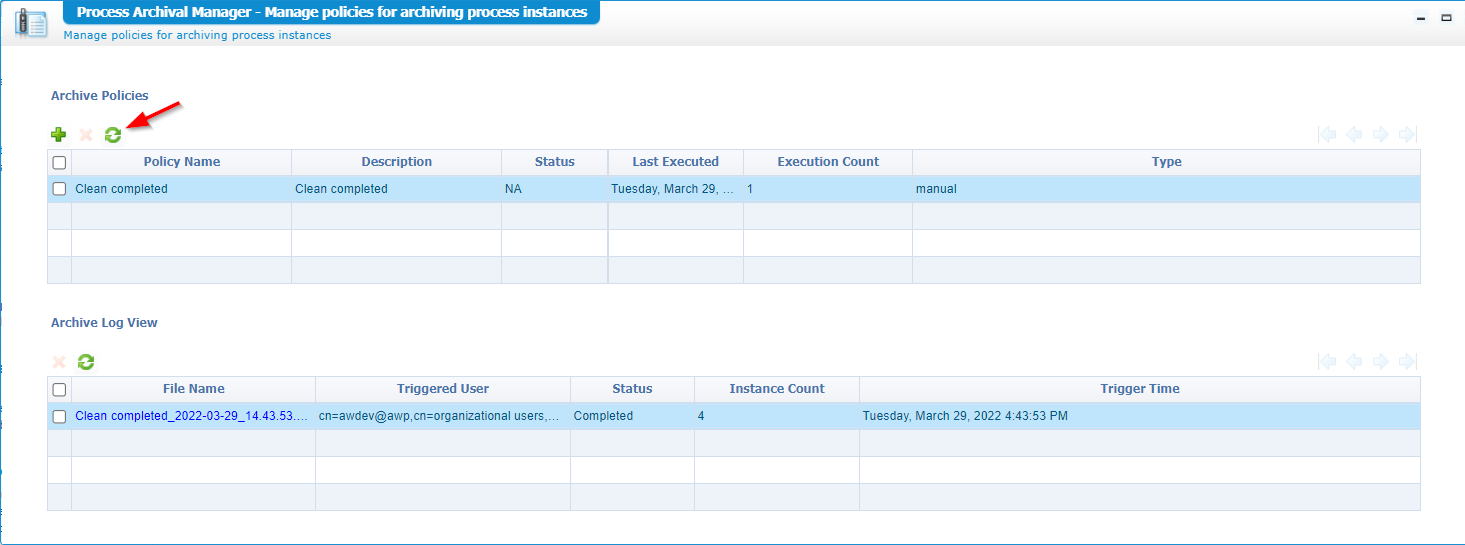
You can double-check the PIM on this one and also the exposed database table!
At the moment, I have four cleaned flows. Click the ‘blue’ link in the ‘Archive Log View’ panel to download the archived ZIP-file!
What is available in this file:
log.xml: Archive info with AWP data source information, and the next three related fileslog-{transaction_id}: Contains the running flow instance IDs of the BPM (template/model){transaction_id}: Contains more details on the flow instances (incl. the activities, variables, message map, and owners)DesignTimeDataCopy_{transaction_id}: Contains the BPM template/model information itself
Back to the properties of our policy again and jump into the ‘Schedule’ tab where we can set several schedule-types. Like a bi-daily one:
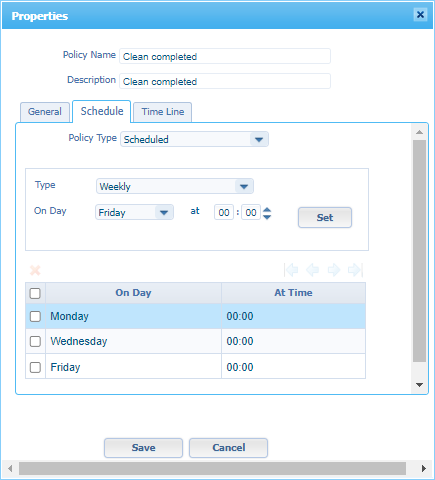
The schedule is inactive by default! From the context menu you can make it ‘Activated’. Will it run at that moment in time? This depends on the ‘Scheduling’ service container in the ‘System’ space…Have a look and make sure it’s running, so it can pick up our defined schedule.
You can even open the ‘Schedule Manager’ artifact to view the schedule ID but do not undeploy it from this artifact! Always use the ‘Process Archival Manager’ for this action! That’s just my experience.
Open questions
Time to get an answer on some interesting questions I asked myself during the above exploration:
Where is the ZIP file eventually stored?
I see that one BPM entry makes the ZIP 5Kb (my four instances give a ZIP of 6Kb). So, that makes one entry roughly 1 / 3 ~ 0,33Kb! This is smaller than the previous database entry, but where is the ZIP stored and will it be removed too?
A little Chrome developer-console skills on the archivemanager.caf file brings me to a function called function showLink(fileObject) {...}. This function builds a download URL like this: http://192.168.56.107:8080/wcpdev/cpc/admin/archive/Clean completed_2022-03-29_14.43.53.4353.zip. From experience, we all know it corresponds with this file location on the server: /opt/opentext/AppWorksPlatform/defaultInst/webroot/wcpdev/cpc/admin/archive/Clean completed_2022-03-29_14.43.53.4353.zip
So, a directory to monitor: sudo ls -ltr /opt/opentext/AppWorksPlatform/defaultInst/webroot/wcpdev/cpc/admin/archive/
For your information on the CAF file:
- Direct URL from runtime: http://192.168.56.107:8080/home/appworks_tips/com/cordys/bpmengine/archiving/archivemanager.caf
- Location from the ‘XMLStore Explorer’ artifact:
/Collection/Cordys/WCP/XForms/runtime/com/cordys/bpmengine/archiving/archivemanager.caf
Is the file removed when we delete the log view entry from the ‘Process Archival Manager’ perspective? Trust me…It’s indeed removed from that file location on the server! 😅
What can we do with this ZIP?
A valid question!? Only I don’t have a direct answer…Archive it externally to a larger data-lake for further AI-analytics? On the other hand, we can also back up the process_instance table from a database perspective and clean up the table manually!? It’s all up to you, and you’re not the only one!
An interesting call from PostgreSQL (just for my own registration):
This is my dump for the same BPM instances information.
THERE IS MORE (an after-update on my own post!)
After some sleepless nights I found the holy grail on those ZIP files! Or I just #RTFM (Chapter 19 of the admin guide!) 🤗
How about view/restoring those archived process instances! Is this possible? Ohw yeah…it’s possible! Let’s have a look at the artifact called ‘Archive Administration’ within our own organization. You will start with an unavailable service group error to manage requests for this artifact. To fix this, we quickly create a new (never used from my standpoint) service container within the ‘System Resource Manager’ using this input:
- Type:
Archive Administration - Group name:
archive_admin_service_group - At “the one” service interface available
- Service name:
archive_admin_service_container - Startup automagically
- Assign to OS process (recommended by OT)
- Connect the ‘Cordys System’ database from the ‘System’ space/organization
Once the service container is up and running, you get a second error from the ‘Archive Administration’. This time about unavailable tables in our database (the one selected in our service container). Time to add those tables through psql:
1 | sudo -u postgres psql |
One of the created tables in these scripts is
process_instance_arcwhich we would like to monitor from a HeidiSQL perspective via a select statement.
Back to the ‘Archive Administration’ artifact where we can now import our ZIP-file to reload the archived process instances:
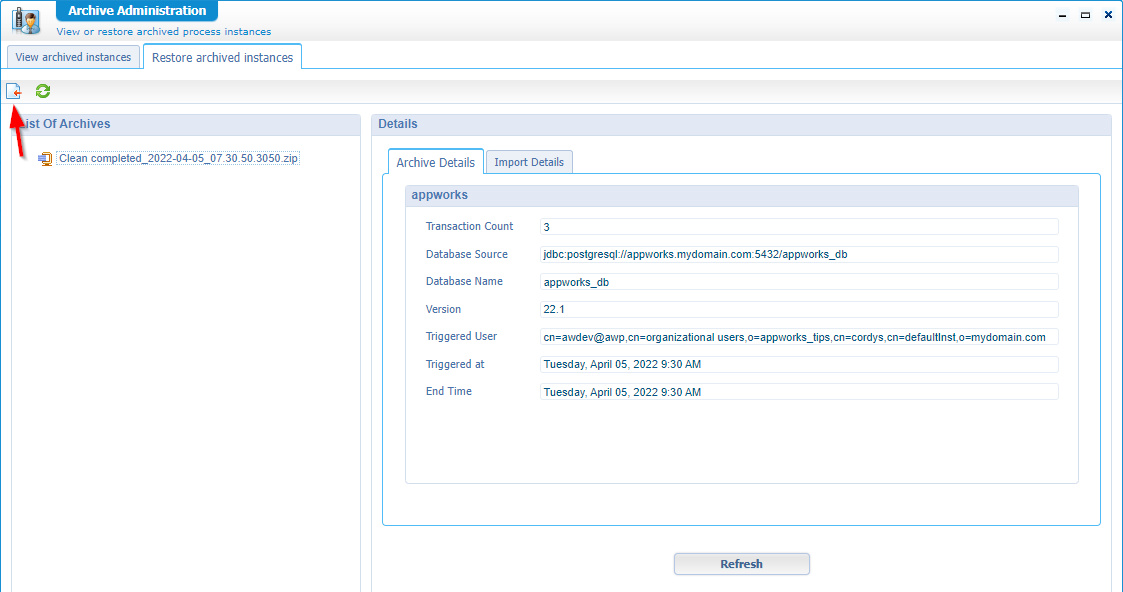
During my own exploration I see a strange behavior as the loading of the ZIP file inserts entries back into the
process_instancetable. I would expect to have insert statements on theprocess_instance_arctable!? A bug? My environment? To solve this I copied the rows from theprocess_instancetable to theprocess_instance_arctable. Both tables have the same column definitions!
Eventually you’ll get an overview of archived process instances from the ‘View archived instances’ tab where you can also apply a filter to find the correct information about your process instance:

NICEEE! 😎
…
A final thing to know is the archive webservices availability through the webservice-interface-runtime-reference (scrabble?) for Method Set Archive Administration (categorized under the package ‘Cordys Business Process Engine’).
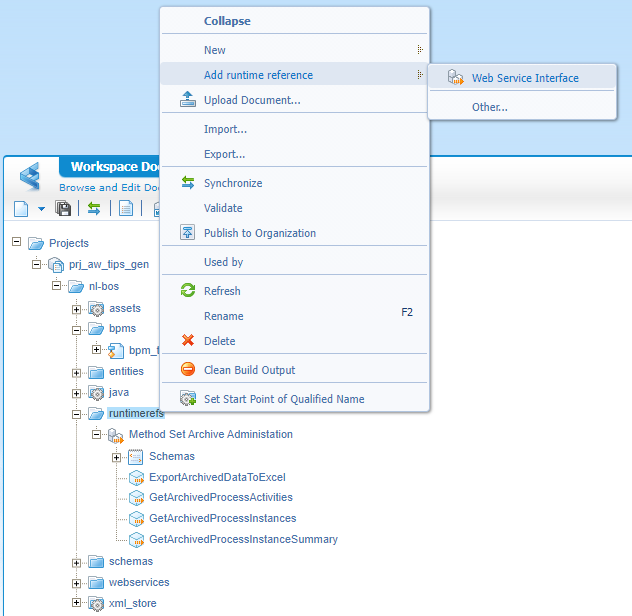
This runtime reference exposes webservices with SOAP messages like this (cleaned from namespace declarations):
1 | <SOAP:Envelope> |
Or another example like this:
1 | <SOAP:Envelope> |
That’s it my friends…We’ll wrap it up with a “DONE”! Always nice to see how things work in the back-end. Again an interesting dive at database- and filestore-level. Share your thoughts in the comments, and I see you in the next one…
Don’t forget to subscribe to get updates on the activities happening on this site. Have you noticed the quiz where you find out if you are also “The AppWorks guy”?
